Compétence technique
Diagnostic & résolution complexe
Remonter à la cause racine pour résoudre durablement, pas seulement traiter le symptôme visible.
Ma définition
Le troubleshooting réseau, c'est résoudre des problèmes dont les symptômes sont souvent flous, les causes multiples, et le contexte sous pression. La méthode compte autant que la technique : isoler les variables, progresser couche par couche dans le modèle OSI, et distinguer les corrélations des causalités. Un bon diagnostic ne cherche pas seulement à rétablir le service : il cherche à comprendre pourquoi le problème s'est produit pour éviter la récidive.
Dans un contexte comme Criteo, où un incident peut impacter 2 000+ collaborateurs dans plusieurs pays simultanément, la capacité à diagnostiquer vite et juste, le tout sous pression, est une compétence critique. Un workaround mal documenté peut masquer un problème plus profond qui resurgira au pire moment. La tendance actuelle dans le secteur va vers l'observabilité proactive (Grafana, Datadog, NetFlow) pour détecter les anomalies avant qu'elles ne deviennent des incidents : le troubleshooting réactif reste indispensable, mais l'enjeu est désormais de le rendre de plus en plus rare.
Points clés
Méthode OSI
Progresser couche par couche pour isoler les variables et distinguer les corrélations des causalités, pas seulement traiter le symptôme en surface.
Sous pression et à grande échelle
Quand un incident peut impacter 2 000+ collaborateurs dans plusieurs pays, diagnostiquer vite et juste est une compétence critique.
Résolution durable
Un workaround mal documenté masque le problème et garantit la récidive. La cause racine est l'objectif, pas le rétablissement du service seul.

Mes éléments de preuve
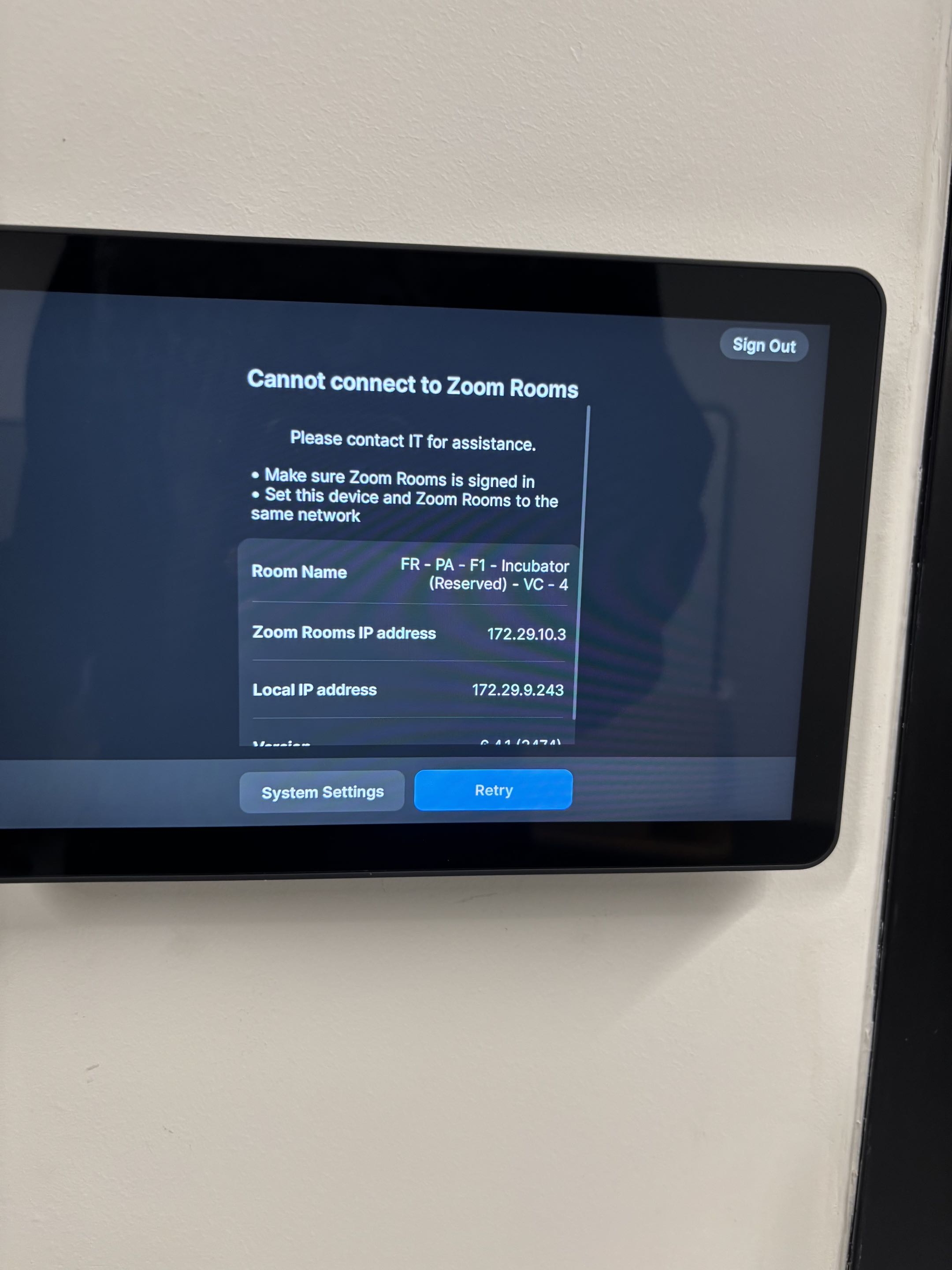
Auth Wi-Fi mondiale → : deux problèmes distincts en Lab
Lors du déploiement de la nouvelle authentification Wi-Fi Meraki via Azure AD/Entra ID, deux problèmes distincts sont apparus en Lab. Le premier était un échec de token STS : le walled garden configuré sur le SSID ne whitelistait pas les endpoints Microsoft nécessaires à la création du token OAuth 2.0. L'utilisateur n'ayant pas accès à internet avant auth, il ne pouvait pas compléter le handshake avec Entra ID. La documentation et les études faites en amont nous ont aidés à trouver rapidement la root cause. Correction : enrichissement du walled garden avec les URL Microsoft documentées.
Le deuxième problème concernait les terminaux mobiles sur les sites de Barcelone et Yerevan : la page de sign-in Microsoft ne chargeait tout simplement pas, résultant en une boucle infinie. L'hypothèse principale est liée au Multipath TCP (MPTCP) : quand l'utilisateur se connecte au Wi-Fi depuis son téléphone sans accès internet, le téléphone considère le Wi-Fi lent et ouvre un lien de backup via le cellulaire, ce qui casse le flux OAuth 2.0. Ce point reste en cours d'investigation.
Extension réseau → (post-RTO)
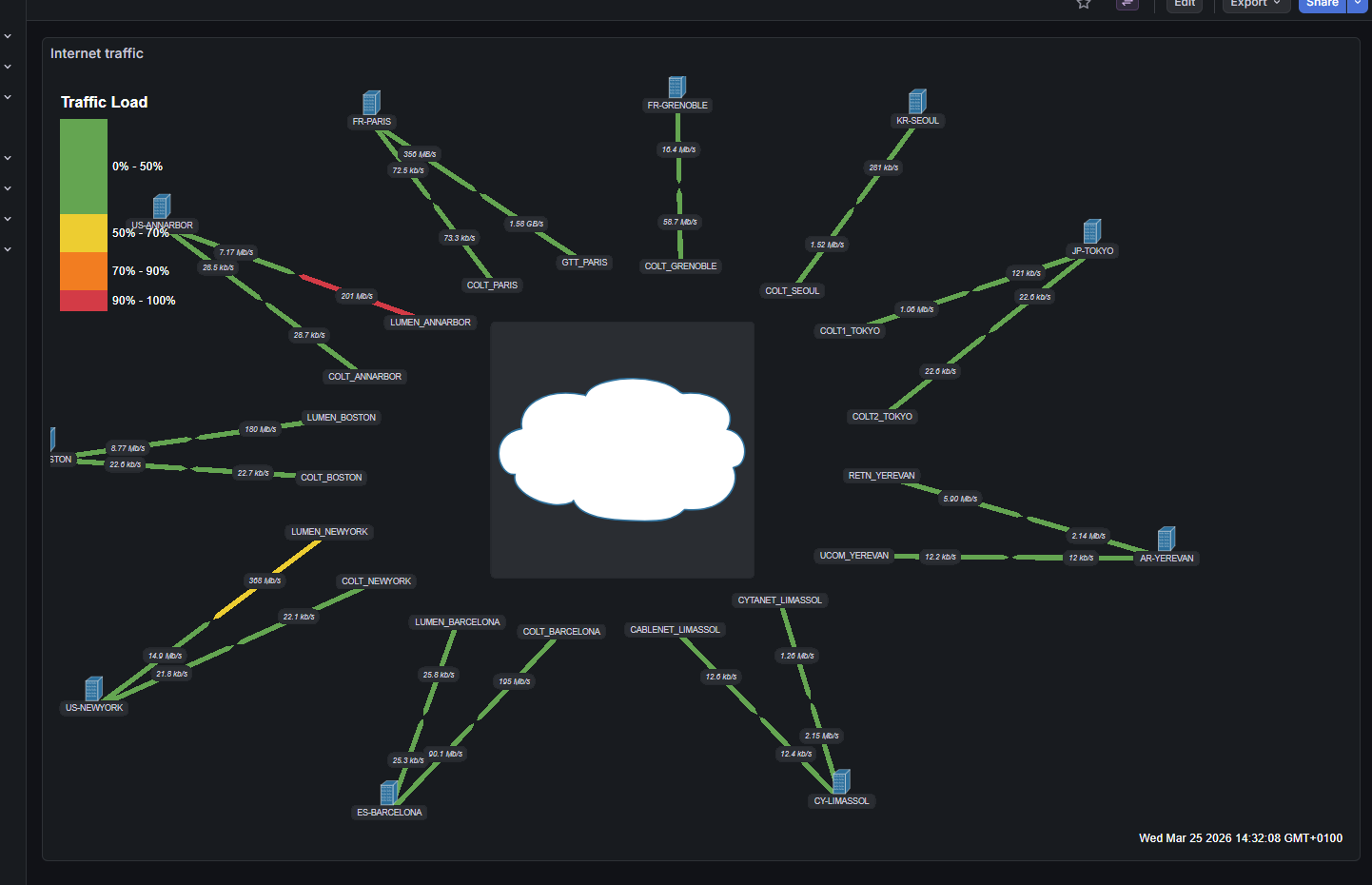
Suite à la mise en place d'une politique RTO (Return To Office), on s'est rendu compte que nos anticipations ne permettaient pas de gérer la nouvelle charge dans le Hub. Grâce au PoC de monitoring Grafana et une analyse complète des métriques, on a pu cibler la root cause : la charge était concentrée à un seul endroit (salle de réunion avec des users avec parfois jusqu'à 4 devices connectés) pour 1 ou 2 APs. La réponse a été de baisser le seuil de roaming entre APs pour faciliter la répartition de charge, et de réduire les canaux Wi-Fi de 40 MHz à 20 MHz pour fluidifier l'accès.
Points clés
Analyse walled garden OAuth 2.0
Identification des endpoints Microsoft manquants dans le walled garden bloquant la création du token STS avant authentification.
Hypothèse MPTCP mobile
Investigation en cours sur la boucle infinie de sign-in sur terminaux mobiles liée au basculement cellulaire pendant le handshake OAuth 2.0.
Optimisation RF post-RTO
Analyse Grafana des métriques de charge Wi-Fi ayant conduit à ajuster les seuils de roaming et réduire les canaux de 40 à 20 MHz.
Autocritique
Mon point fort est l'analyse multi-couche et la capacité à ne pas m'arrêter au symptôme visible. Ma marge de progression est sur la vitesse de tri d'info initial : quand plusieurs incidents arrivent simultanément, j'ai tendance à creuser trop profond sur un problème avant de m'assurer que c'est bien la bonne issue à escalader vers un expert spécifique.
Ce que je conseillerais avec le recul : documenter le diagnostic en temps réel, pas uniquement la solution. La prochaine personne qui rencontrera le même problème a besoin de comprendre le raisonnement, pas seulement le fix.
Cette compétence s'est affinée par l'exposition directe aux incidents production, la progression est moins linéaire que pour une technique, mais elle est réelle et continue. Dans mon profil, c'est une compétence transverse qui valorise toutes les autres : une infrastructure bien conçue ne sert à rien si on n'est pas capable de diagnostiquer ce qui part en prod.
Points clés
Point fort
Analyse multi-couche et capacité à ne pas s'arrêter au symptôme visible pour remonter jusqu'à la cause racine.
Point de vigilance
Sur incidents simultanés, tendance à creuser trop profond sur un problème avant de s'assurer que c'est la bonne issue à escalader.

Mon évolution
Je souhaite monter en compétences sur les outils d'observabilité réseau (Grafana, NetFlow, Datadog Network Monitoring) pour passer du troubleshooting réactif à une détection proactive des anomalies. L'enjeu : capter les dérives de baseline avant qu'elles ne deviennent des incidents.
Je prépare en autoformation la certification Cisco Network Security (CyberOps Professional) pour formaliser la dimension sécurité de l'analyse réseau, au-delà du diagnostic technique pur.
Points clés
Observabilité réseau
Montée en compétence sur Grafana, NetFlow et Datadog Network Monitoring pour détecter les anomalies avant qu'elles ne deviennent des incidents.
Du réactif au proactif
Capter les dérives de baseline avant qu'elles n'impactent les utilisateurs : l'enjeu du troubleshooting dans les grandes infrastructures.
Réalisations rattachées
Cette compétence s'est exprimée principalement au travers des projets suivants :
Points clés
Modernisation auth. Wi-Fi
Diagnostic des échecs de token STS et investigation MPTCP sur terminaux mobiles lors du déploiement Meraki/Azure AD.
Extension réseau zéro-coupure
Analyse Grafana de la charge Wi-Fi post-RTO et optimisation RF (seuils de roaming, canaux 40 → 20 MHz).